Video Observability
As a television broadcaster, how do I ensure that my channels are playing out the right thing for my viewers?

As a television broadcaster, how do I ensure that my channels are playing out the right thing for my viewers? Well, usually by watching and listening to it!
In the old days you would have a handful of channels, each broadcasting video and audio in a single language. You would hire an operator to sit in front of a few monitors and watch them all simultaneously.
What’s in a stream?
A television stream is made of multiple spatiotemporal elements. Temporally: frames of video are rendered one-by-one in front of your eyes typically between 24 and 60 frames per second. The audio samples run even faster and create the continuous sound you hear. Spatially: within each frame there are visible elements such as overlaid channel branding logos, closed-captions, pop-up graphics to entice you to watch more on the channel and many more. The complexity doesn’t end there. These days there are multiple audio and captions languages streamed at the same time so as a viewer you can choose to watch a show with Spanish audio and English captions for example. Finally, there’s a world of data encoded into non-visible parts of the signal that inform downstream components to perform some action, like deliver local advertisements when they decode a trigger.
You can imagine the task of orchestrating all this complexity to come together into a seamless experience for the viewer! Playout automation services have been taking care of this problem for many years. Given a schedule describing the desired output, the automation controls a myriad of software services and hardware devices in real-time to produce the output stream.
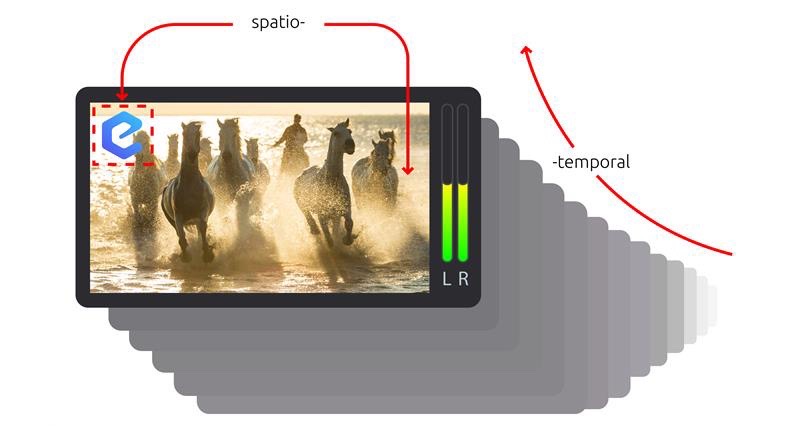
As stations have grown to hundreds of channels, and each channel might have station logos, closed-captions, pop-up graphics and half a dozen audio languages, monitoring has become a much more daunting task. The screens have become a huge video wall, with hundreds of streams visible simultaneously. Operators can select a stream to listen to one-by-one, but without being an amazing polyglot they can at best make an educated guess that what they are listening to sounds Portuguese-ish. But is it Portuguese or Brazilian-Portuguese? You can see how this doesn’t scale.

To help the operators, automated monitoring tools have been developed. These check that the pictures have not degraded in some way or frozen or simply showing black. They’ll check that the audio is not silent and that the captions are present. But, not a great deal more than that.
These monitoring tools, like most monitoring, are only checking for known symptoms. For example, there are many error conditions that could lead to the stream showing black, so detectors were specifically invented to check for black. The trouble is, black sections are often intentional, particularly when transitioning into breaks or before end credits, so you may get false alarms.
What do we want?
To draw an analogy with software unit testing, this legacy monitoring would be like all your tests passing simply because the code runs without crashing! What we really want is a way to check that the stream output matches our intent. A good unit-test asserts that, given a known input, an expected output is observed.
We want to be able to say, “At 8:30pm we should be showing season six, episode ten of “Better Call Saul”, the English, Spanish, French and German audio and captions should all be available. The channel logo should be showing in the top-right of the screen.”
So, give a copy of the schedule to a machine that can watch the stream and report discrepancies. Easy? No.
Humans are really good at answering that question about what should be happening at 8:30pm. They can glance at a small screen, read some notes about the episode and reason that it’s correct. They can check the correct channel logo is in the right place. They can tell the difference between these languages even if they are not fluent. Machines have a hard time with this.
“AI and Machine learning!”, I hear you cry. Yes, these types of problems are becoming more solvable using these techniques but, it’s expensive. Expensive to train and expensive run. It would end up costing more to monitor the channel than to produce it!
What did we make?
For evertz.io we’ve built a cost-efficient way to test, through assertions, that the scheduler’s intent is produced in the output stream. We use statistical methods over perceptual representations of the source content and output stream to produce similarity scores. Thresholds over these scores allow us to pass or fail an assertion.
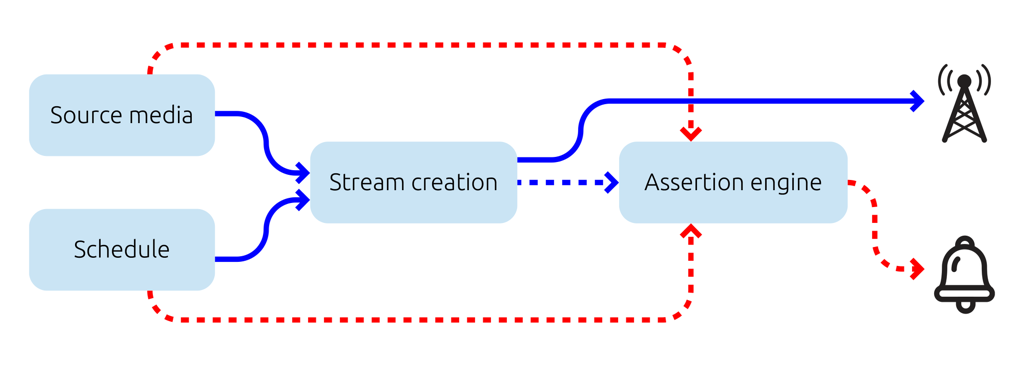
That question about what should be observed at 8:30pm is now answerable. And for 8:31 and 8:32 and 8:33… multiplied by as many channels as you like – the machines do not get overwhelmed. More so, it can do a better job than the human. An assertion will fail if you’re more than a few seconds out from where you should be in a show; an indicator of a problem that may lead to the cliffhanger getting cut off by an ad break! Like human operators, it’s not fluent in those languages, but it can statistically match what should be audible with what actually is. Therefore, it can check that Portuguese, Brazilian-Portuguese, French and Canadian-French are all present in the correct order through pattern matching. Not only that, but the machine will tell you that the correct seconds of the audio are playing at the correct time in the show, not simply, “Hmm, that sounds like French. Pass!”
Our patented technology can do all this and more using a few lambda functions and a single ARM CPU core per channel running our Rust assertion engine. Hard to beat that cost optimization!
How do we make sense of it?
With assertions for every few seconds, when there is a failure there is a lot of data to comb through. And even once you’ve identified which spatiotemporal element is causing the failure, how do you go about identifying the cause? A modern playout chain is made up of a lot of moving parts, and a failure in any one of them could cause similar looking problems in the output.
By using Honeycomb to collect distributed tracing data across all elements of the playout chain, we can easily filter and zoom in on assertion failures. We can then use assertion trace attributes in queries across the services in the playout chain and pinpoint where the issue originated.
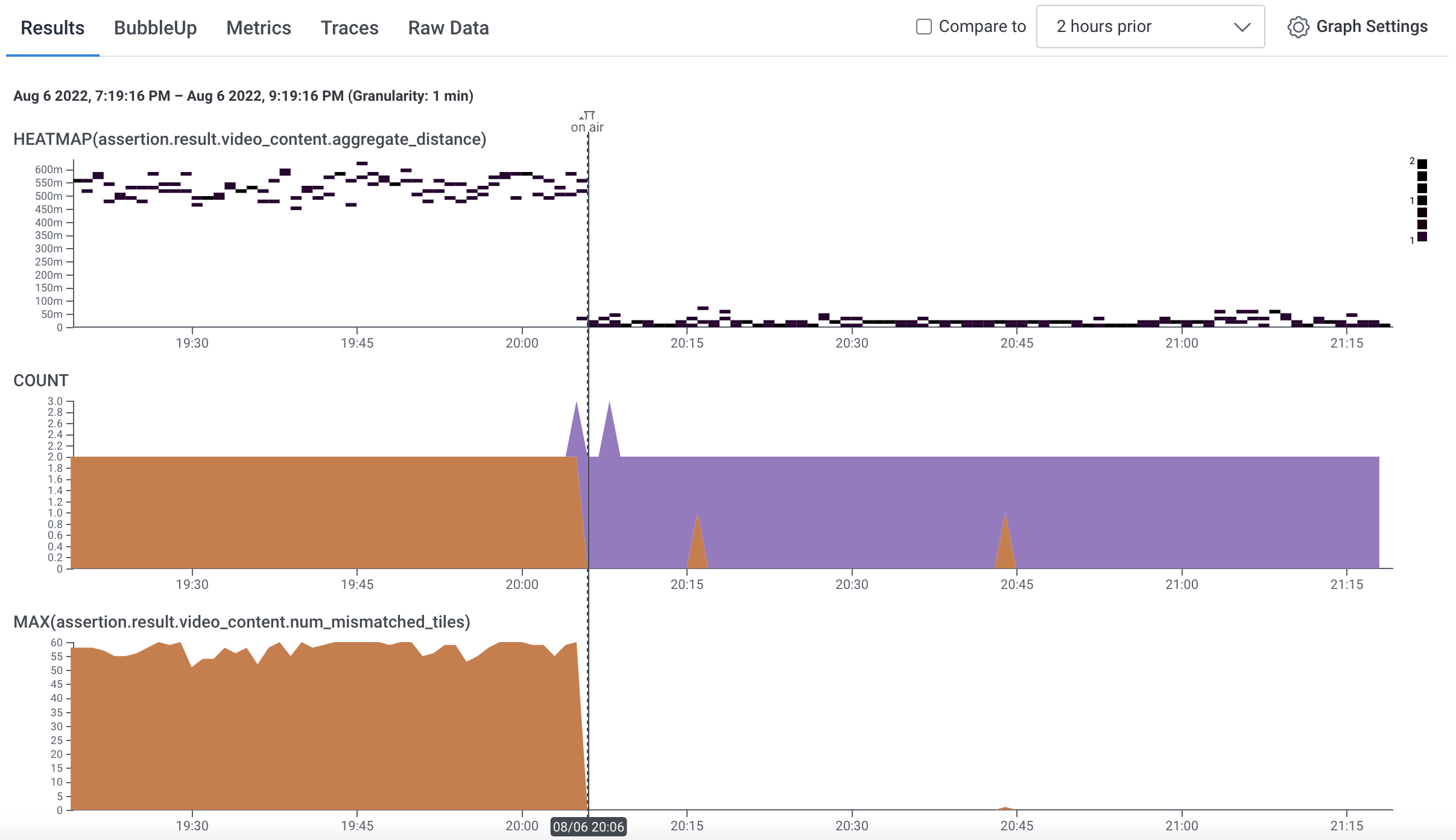
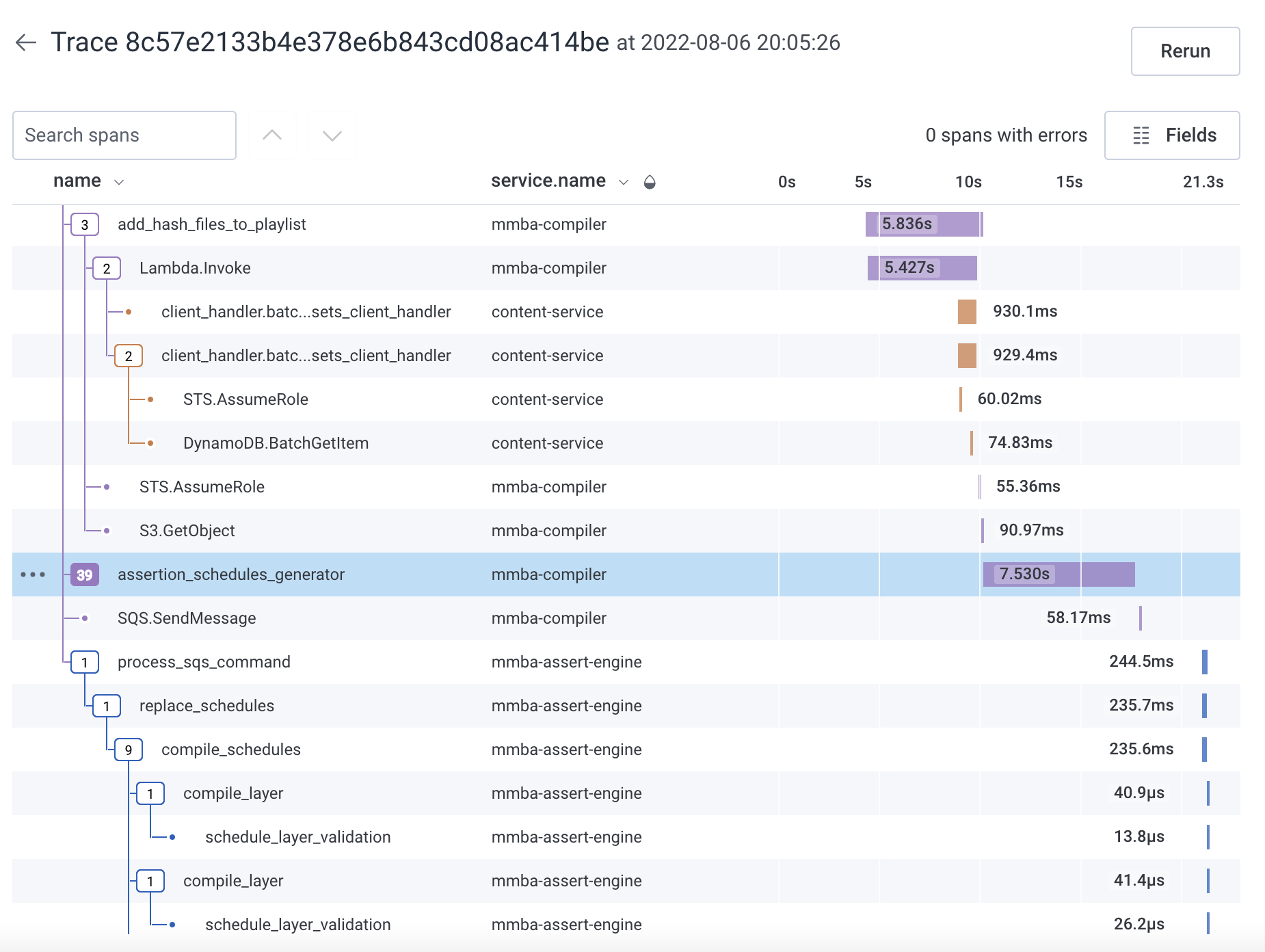
To help understand the failures, we attach a link to the Honeycomb spans to our own tooling to visualize an individual assertion report:
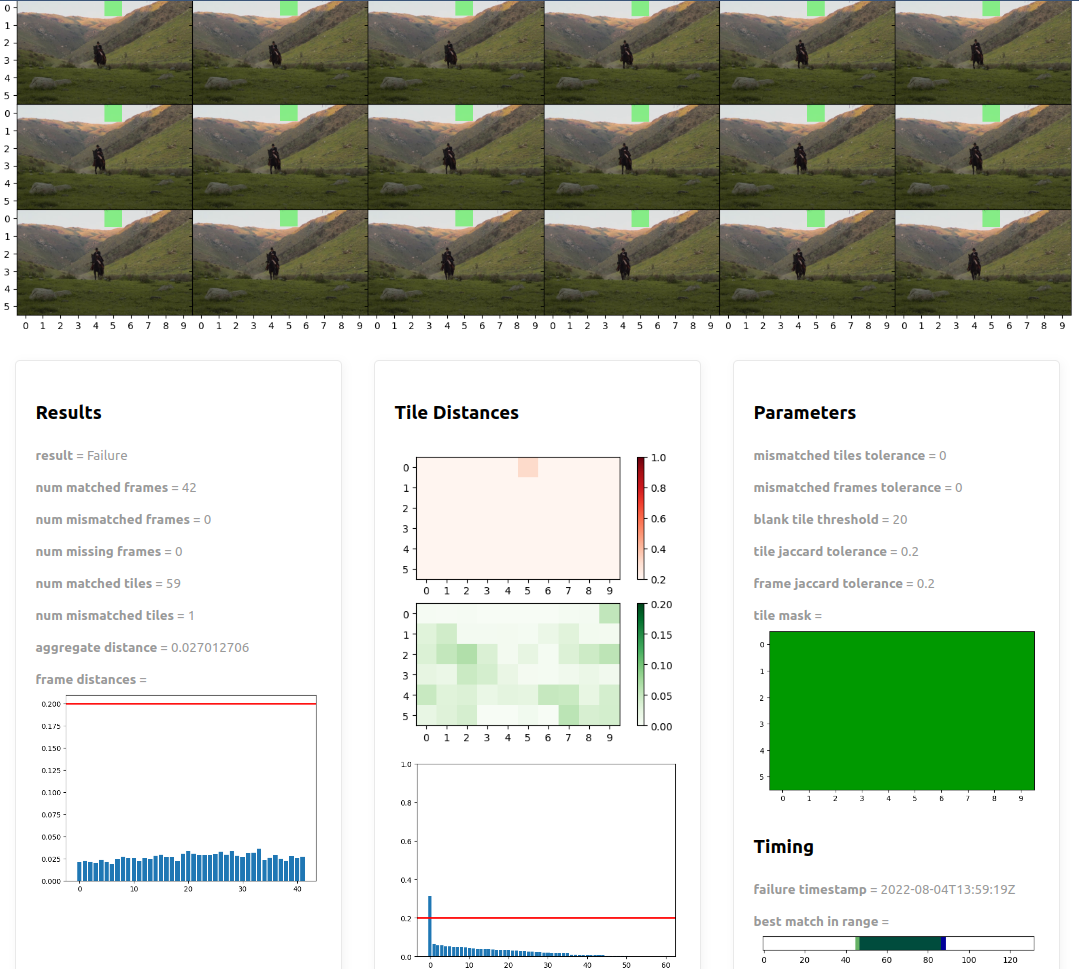
Not only can we get the detailed report but we can look back at the timeline of events that led up to it. By slicing and dicing the data we can look for trends, groups, previous outcomes given similar inputs, you name it! There’s a wealth of data to dig into.
With video observability we can ensure our production system is running smoothly. Our distributed tracing and high-cardinality data in Honeycomb allows us to connect assertion outcomes to scheduled intent. We can safely deploy and release new versions of code to production multiple times a day; first to a dogfood tenant and then a gradual roll-out to our customers. We can analyze not only the performance of the new code but the correctness of the output stream. Through integrations and webhooks we can even automatically trigger a rollback to the previous release to resolve issues much faster than any human-in-the-loop monitoring and incident management process.
